What To Do When Your Website Content Gets Scraped
Sometimes, imitation is not the most sincere form of flattery -- especially online. Here's what to do if you notice your content has been scraped.


We excel at building websites. It’s what we do. It’s what we love.
We love when people take notice of our websites! However, some people can love our websites a little too much.
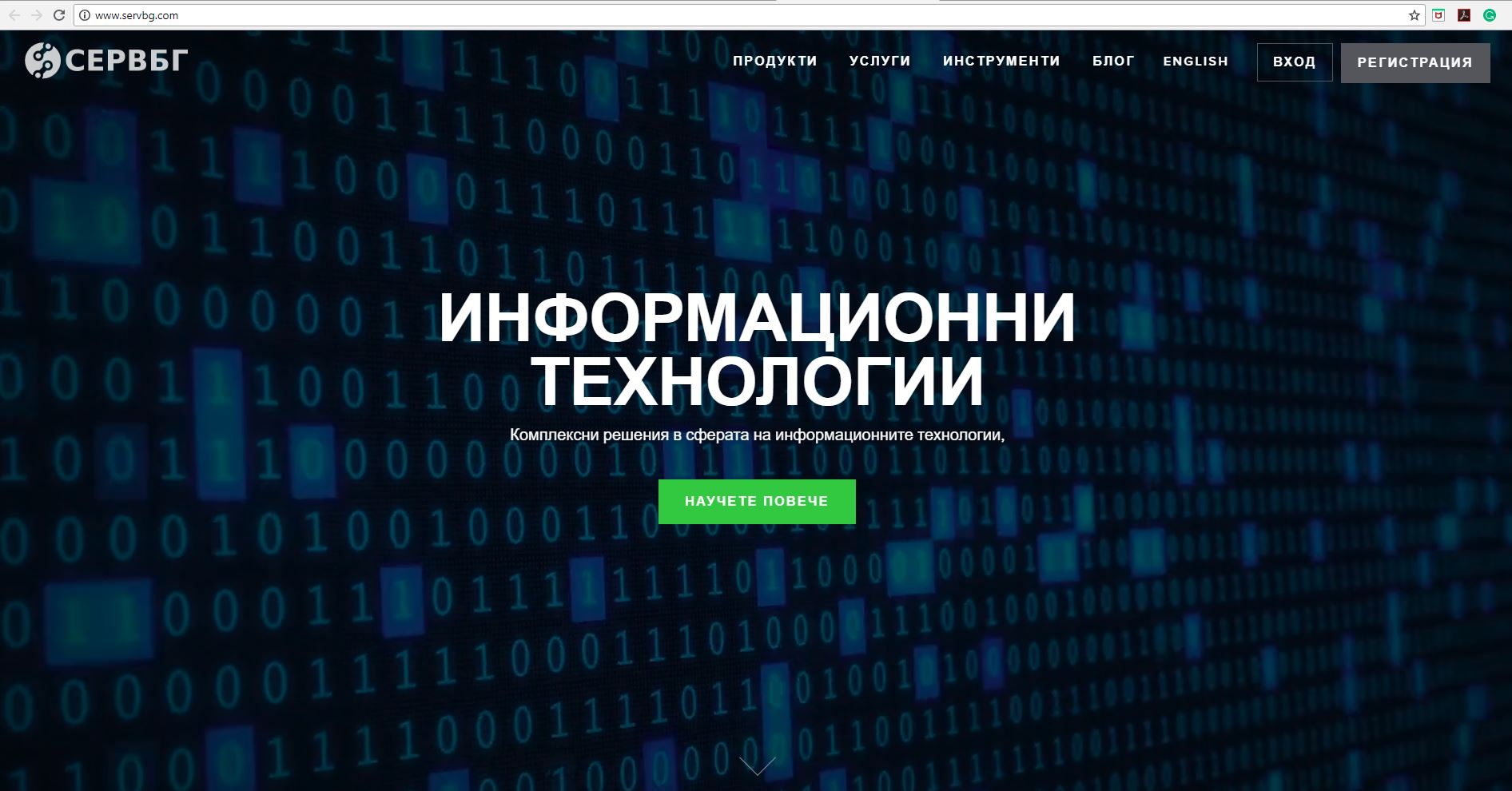
Yes, this is our old website -- apparently scraped by what appears to be a Bulgarian IT company? Whoever they are, they managed to keep our entire "Popular topics" section the exact same as how we had it before launching our new site.

And we realize we’re not alone in this whatsoever. Content, images, and even entire websites get scraped daily. But what is online scraping? Why is it an issue? And most importantly, what should someone do whenever they realize they’ve gotten intellectual property scraped by another person or organization online?
What is Website or Content Scraping?
Scraping is the business equivalent of identity theft. It's never a comforting moment to realize your company's hard work has been duplicated in a short turnaround by another organization or website.
Why Content Scraping Matters
Loss of competitive advantage
Building your brand voice through content, visual elements, and web design takes time. However, seeing someone else out there with your content or website cheapens the work you put into building your organization’s brand. And if scraping happens within the same industry, the commonalities between your business and a potential competitor could leave your business shorted on competitive advantage.
Duplicate content is penalized by Google
The second point is probably the most frustrating. With the Google Panda algorithm penalizing sites that have content duplicated, it’s become way more important to have your content be entirely original. However, website scrapers and content scrapers can successfully trick Panda into thinking they’re the actual creators of the content. And unfortunately, this means your website is the one that gets penalized for the duplicate content – not the thieves.
How to Find Out if Your Content Has Been Scraped
To be honest, our team isn't 100 percent certain how we stumbled upon the scraping website. It was a random happenstance. We were looking for captcha information, and this result caught our eye on Google's page one. When it boils down to how we found that our content had been scraped, serendipity. That's how.
If you’re really paranoid about your content being scraped, you can outsource that paranoia to a service like Copyscape’s Copysentry that sends out automated plagiarism alerts.
If you suspect that your property has been scraped, make sure you’ve actually been copied directly. It’s not uncommon for talented people within the same industry to have similar ideas or design inspirations. Stylistic choices, web elements, and seemingly standard content can be harder to claim ownership of, but your content, images, and website code? In terms of content, this can be effectively treated. There are a number of free plagiarism checkers online for your copy. You can also tap into a reverse image search on Google or Tineye to find different versions of images owned by your organization.
So, Your Content Was Scraped. What’s Next?
First off, don’t panic. This happens a lot, and the scraping won’t affect your website’s performance or ranking as soon as it detects duplicate content. Sometimes, those who scrape websites and content are just opportunists looking to build their business a bit more off the backs of more successful companies. This can be a startup in desperate need of a good-looking website or content piece to impress investors. They often (like the culprit behind our scraping incident) lack the skills to cause serious damage to your website’s performance.
Be cautious, however. There are some malicious scrapers who go beyond a poor copycat routine and have the market analysis and skill set to lift an entire website with ease.
How to Stop Content and Website Scrapers
1. Run a Whois Lookup and discover who owns the domain.
This can get tricky if it’s an international owner from some random country (like Bulgaria in our case…). There should be an email address associated with who owns the domain. If you find an email, move onto the second step.
2. Send an informal cease-and-desist.
No, nothing about this should be legal. However, contact the website owner first and ask them to remove the site or the duplicated content. They might claim the scraping happened out of ignorance and remove the content or scraped material entirely. But you should at least reach out to them first.
3. Go to the domain or hosting company directly.
If you don’t have the admin contact’s email address, you can at least see the domain registrar or the hosting company for the website. Try contacting both companies and let them know one of their domains is stealing copyrighted content. The companies should run a quick diagnostic to confirm your story and then possibly suspend or remove it.
4. File a complaint with Google via DMCA.
Or you can always go straight to Google itself. Any website or content owner who thinks their website has been stolen by another organization can ask Google to deindex pages with the stolen content under the Digital Millennium Copyright Act. The tech behemoth might take awhile to process your claim of alleged copyright infringement, but it's better than not filing the claim.

Shelby Rogers
Contributions Editor here at Solodev. Want to be featured on the Solodev Blog? Get in touch.
Follow me on Twitter